tomcat架构
web需要做的事情:
- 协议解析
- 业务处理
因此tomcat设计了两个核心组件连接器Connector和容器Container来分别做两件事情。连接器负责对外交流,容器负责内部处理。
连接器
连接器和容器要结合起来对外提供服务,tomcat有个组件将他们组合起来service.一个tomcat可以有多个service,可以实现不同的端口号来访问同一台机器上部署的不同应用。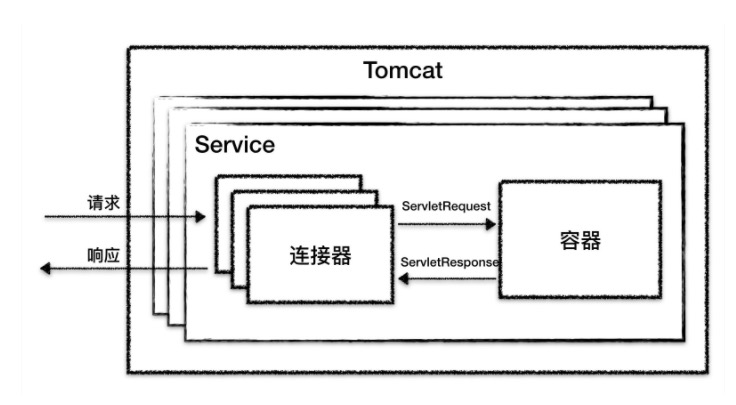
Connector处理的工作又可以分为网路通信,协议解析,与容器交互。因此tomcat设计了3个组件和实现这个3个功能,分别是Endpoint,Processor,Adapter。Endpoint负责提供字节流给processor,processor解析相关的协议,封装成Tomcat Request对象给Adapter,Adapter负责提供ServletRequest对象给容器。因为io模型和应用层协议可以自由组合,tomcat将Endpoint和Processor放在一起考虑,设计了一个组件ProtocolHandler。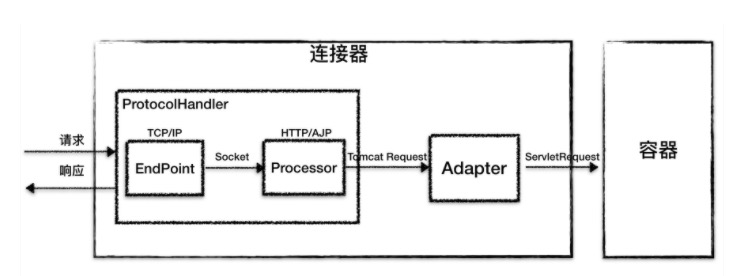
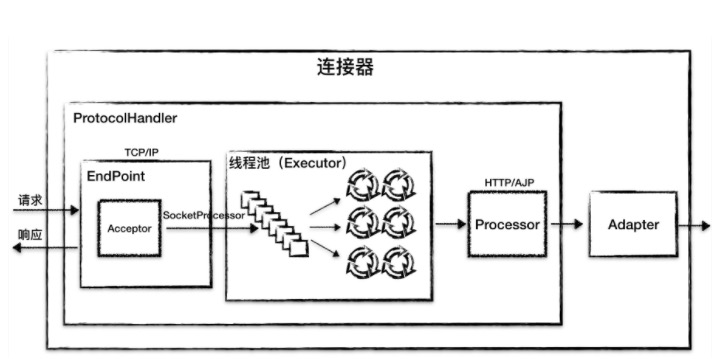
tomcatio模型为reactor模式,Endpoint有两个子组件Acceptor和SocketProcessor,SocketProcessor提交到线程池来执行。
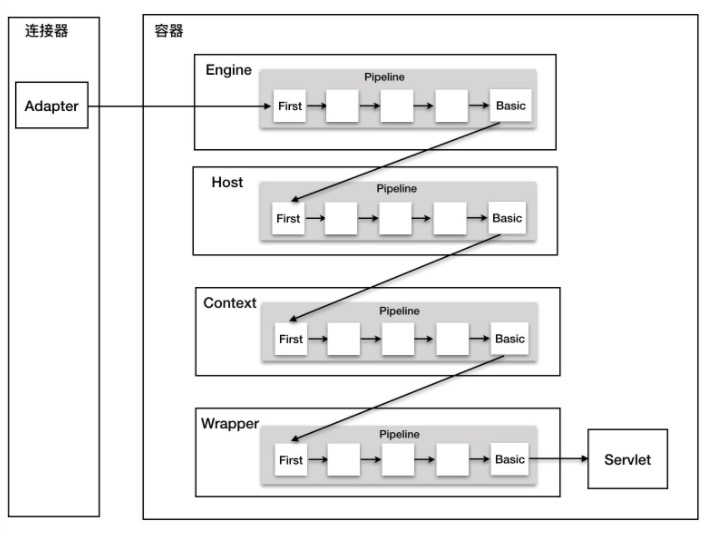
容器
tomcat容器采用分层架构,每层处理响应的事情。分别是Engine,Host,Context和Wrapper.
这四种容器不是平行关系,是父子关系。
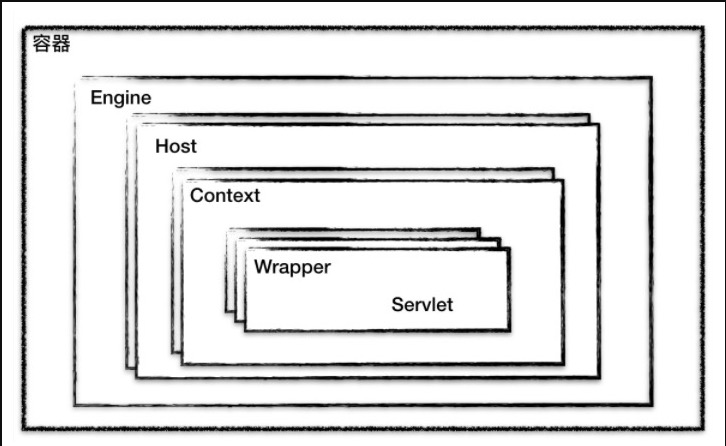
engine
根据Engine类上面的注释我们可以了解到,它在两种场景下产生作用:
- 想通过拦截器来查询所有引擎对单个请求的处理
- 想运行一个单http连接器,但是想支持所有的虚拟url请求
通常我们是不需要使用engine的。
host
域名处理。tomcat可以根据不同的域名访问不同的context。可以根据不同的host转发到不同的context。
context
我们部署的每个web应用其实最后被加载为了一个context。每个context有不同的context-path。context中持有servelet,根据不同的url请求到响应的servlet进行处理。
wapper
具体处理业务逻辑的地方
定位一个servlet
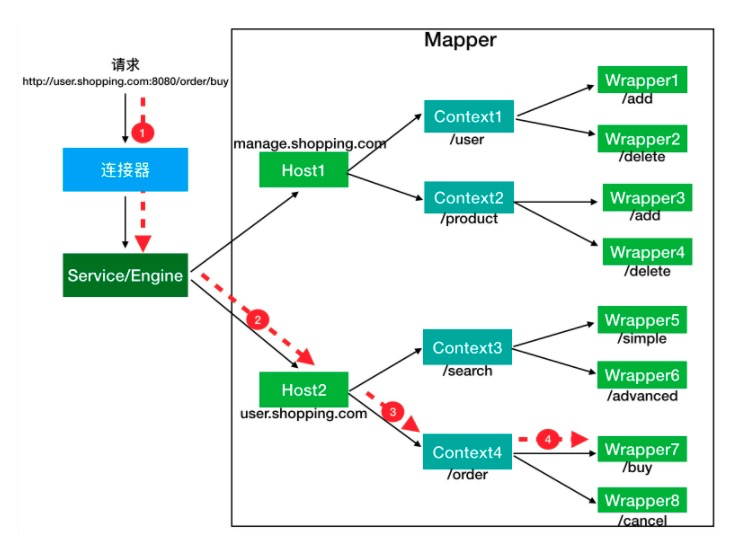
责任链模式
tomcat所有容器都继承了一个相同的父类Container,从开始父类进行处理,处理完之后调用子Container。采用pipeline模式,pipeline持有一个value的链接。所以pipeline有一个getBasic方法,在value链的末端,负责调用子类的第一个value.
1 | public interface Valve { |
value看起来跟filter的代码很像,value是tomcat私有的,filter是servlet规范支持的。